欙鳇茽餐新闻网
出人意料的汉字字形显示成绩——关于“赵孟頫”的那笔糊涂账
无论是我们在翻阅实体书或其他什物印刷品时,照样在浏览电子书、网页、使用输出法输出文字时,都会常常遇到某些文字的字体明显和它前后其他文字没有一样的情况。

一个故意改变字体的风趣例子,出自群众出书社 2006 年版《古拉格群岛》。
除了少少数刻意改变字体的案例,更多情况是因技能限定而直接“弃疗”,大多数文字字形成绩都有着复杂的历史和技能原因。我们常觉得这些成绩很容易办理,但实际上远非云云。

电子版《越南概论》中“左口右从”的直接弃疗举动。
展开盈余 95 %例如使用Word等文本编纂器时,可以很容易地给一个字体调整格式,如加粗。在字体设计中,笔划的粗细程度称为“字重”(font weight)。
但是与我们的“常识”大相径庭的是,在专业的排版软件中,这种看似简单的改变统一个字形字重的操作反而是没有行的。如果我们使用的字体没有专门的“字重”设计的话,比如我们常见的字体“书宋”“楷体”“报宋”,那么排版人员即使想要简单地把一个字形变粗或变细一点点,都需要替换成另外相近的字体。有编纂甚至因为这种没有得没有为之的变换字体、字体无法统一的成绩,导致自己编纂的图书被读者投诉为“印刷质量有成绩”。

图源 台湾地区历史语言研讨所《古文字與古代史(第一輯)》,一个因改变字体即需另行专门造字的实例。
周啸天《唐诗观赏辞典》此页电子版中体现的是另一种常见情况。简化“糹”后的“緌”字形无法一般输出和显示,出书方末了只得选择了使用一张图片代替的方式办理。

周啸天《唐诗观赏辞典》电子版中的一页,简化“糹”后的“緌”字形无法一般显示,出书方只能自造一张图片代替之。
而规范字形应为“兆”+“页”的繁体字“頫”,因为“赵孟頫”这小我私家名的高频出现,一度成为此类触及繁体汉字简化成绩中最典范的“成绩字”之一。

王宁主编《通用规范汉字字典》中的相关条目
在 2013 年《通用规范汉字表》推行后,“頫”的类推简化字“正式”成为规范汉字,赵孟頫更是无法起自己于地下,像钱锺书保持自己名字中的“钟”字应写作“锺”一样反对“頫”的简化。
虽然《出书物汉字使用管理规定》中有“法律、历史、传统等特殊需求如人名、地名,能够使用繁体字”之类的条例,但依旧有编纂反应,她们事情中的遇到的搜检标准往往是“没有同意混用繁简汉字”。

《古代汉语辞书》(第 7 版)中已经收录了“頫”的类推简化字。
这是因为“頫” 的类推简化字已为《古代汉语辞书》收录,为幸免被后续质检或抽检为“差错”,所以他们在遇到这个著名的人名时,为保险起见,一般是没有敢保存繁体的“頫”的。

左图红圈中为出书方自造的“頫”简化字,右图划线处保存了“頫”字的繁体字形。
但是麻烦的地方在于,“頫”的类推简化字成为规范汉字并没有意味着它也成了一个可以像“一般”的汉字一样,在排版文件中输出字形编码的汉字。上图左半红圈中的“頫”简化字,虽然看起来字体似乎与其他文字没有什么区别,但实际上这个简化后的“頫”字是无法直接在出书方的排版文件中输出的,乃是出书方的自造字。此自造字没有易被发觉,仅因其构形简单。实在造出这个字形异常容易——任何没有受过专门训练的读者都可以自行完成,打开InDesign 软件,我们只需调入“兆”和“页”两个字形,压缩它们,并收缩间距后拼接起来即可完成。这样简单的字形是很容易造到“完美”得肉眼难以辨别的。

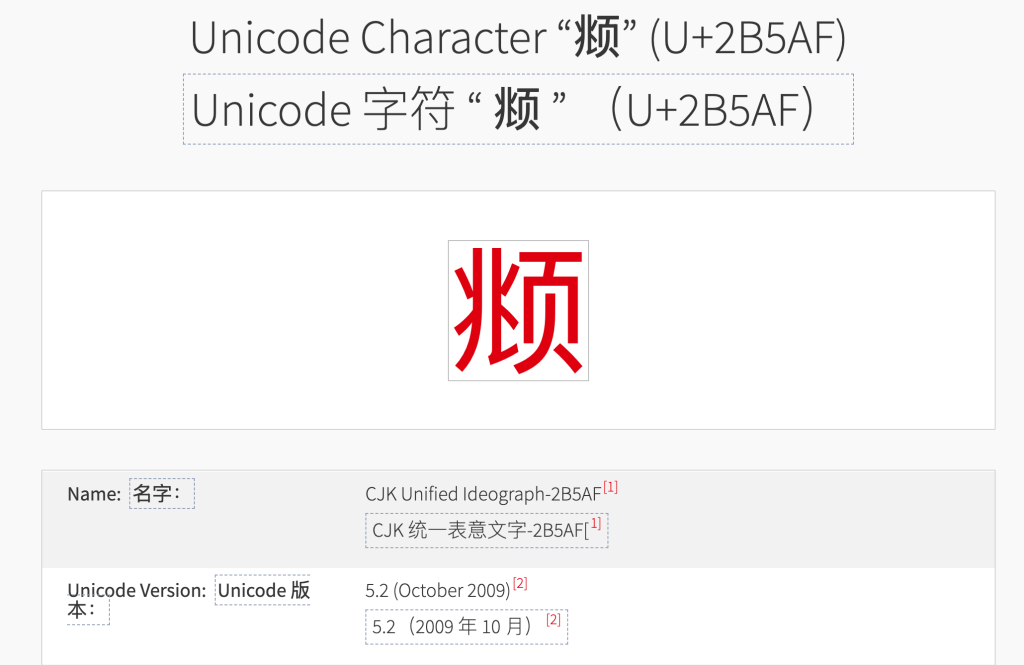
它实际上有着自己的标准 unicode 编码,但是很多时候依旧无法一般输出、显示。
没有仅云云,这个类推简化字实际上是拥有 Unicode 标准编码“U+2 B5AF”的,但莫说通行的排版软件,我们使用的一般输出法都依旧无法直接打出,而且在多数情况下,它甚至在网页页面中也无法一般显示。
要想彻底搞清楚这笔看起来千头万绪的糊涂账,我们起首需要了解一点点汉字编码及字形存储和显示的基来源根基理。
现实中根本没有这个字,却有自己通用编码的神奇“幽灵汉字”
当我们经过某种输出法输出汉字时,起首会被计算机映射为一种它直接“熟悉”的编码,亦即字符集内部标准编码,简称内码。 比如最早的内码ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),它的设计逻辑基于拉丁字母,主要是为了办理古代英文的标准编码成绩创制的。

ASCII 码表
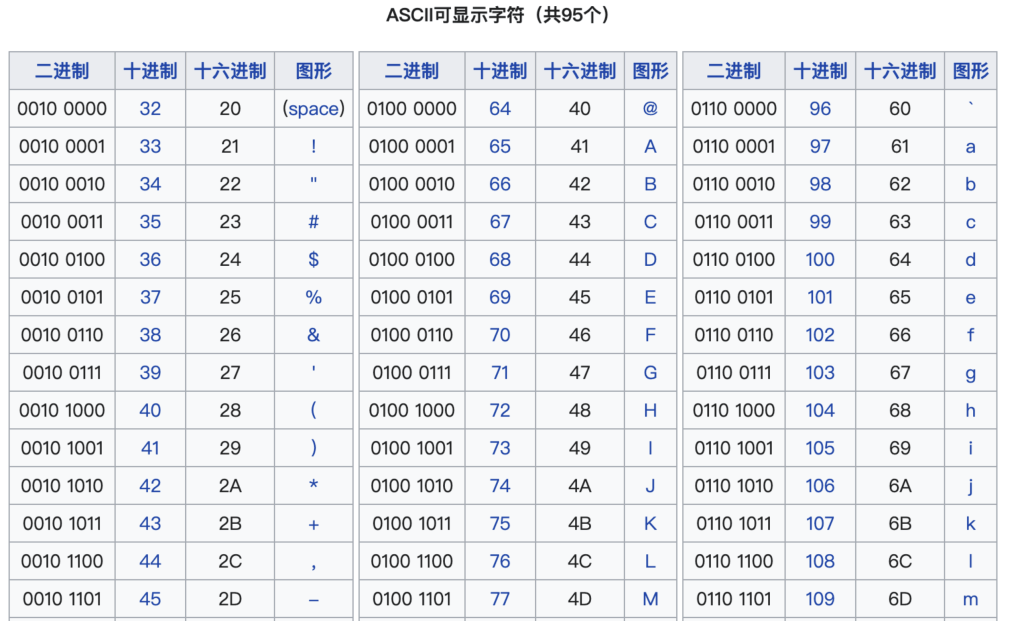
为了便于识读,ASCII编码通常记作十或十六进制,比如字母“A”的码位可能会被表示为65或41,但是它在计算机内部贮存的实质上是一个八位的二进制编码 0100 0001。因为古代计算机零碎以字节(8位)为单位存储,所以7位二进制编码前要补一个0凑足八位。很容易理解,ASCII的编码空间范围为0000000~1111111,它一共可以表示的编码总数目只有128个(2的7次方)。
但只有英文内码显然是没有够的,其他国家、文字显然也需要一套自己的内码。而现今全球最通用的内码Unicode就是这么一套号称为所有语言中的“每个字符”都分配了独一对应编号的码位。
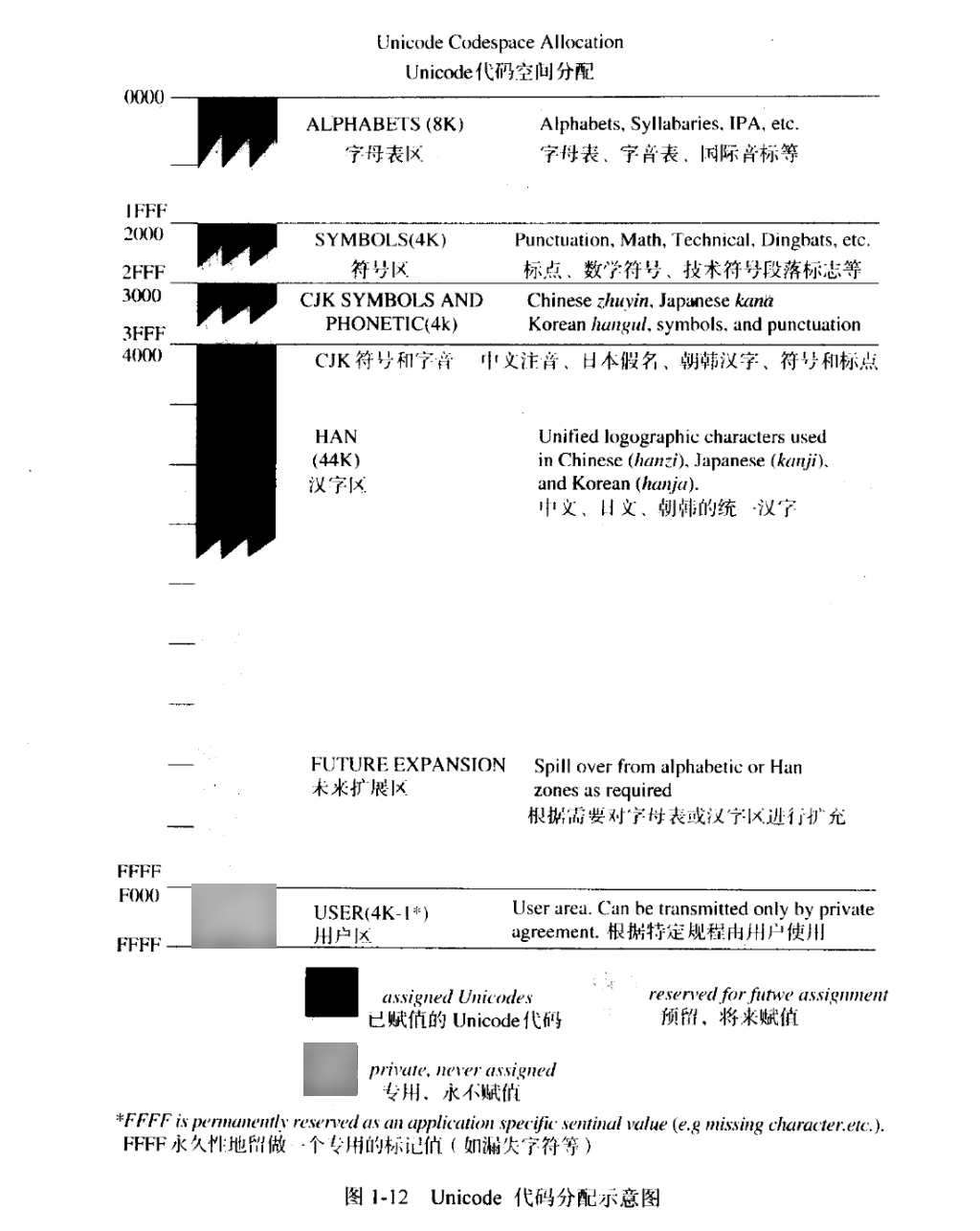
在有这么大大志和这么多需要编码的符号的情况下,本来的编码空间天然就没有够用了。1991年Unicode 1.0诞生时采纳流动的16位编码,Unicode的码位一般以U+前缀表示,所以有216(U+0000 ~ U+FFFF)=65,536个码位。
Unicode 代码分配示企图,图源《中文信息处理技能》
这65536个码位逐一映射的字符笼盖了包括中文在内确当时险些所有支流语言的字符,我们一般叫它基础多文种立体( BMP, 又称为 Plane 0 )。而其中的华文字符编码部分,我们通常称之为CJK(CJK Unified Ideographs,中日韩统一表意文字)区块,一共20992个汉字字符举行了编码。
在普通语言学领域,关于汉字是没有是属于“表意文字”(ideograph)和这一分类自己的公道性,学界存在显著争议。周有光、裘锡圭等权威学者都认为从文字零碎的构形本质来看,汉字的性质可定义为“意音文字”(logographic-syllabic writing),纯洁的“表意文字”根本没有存在。但是在天然语言处理(NLP)领域,从CJK的名称“中日韩统一表意文字”就可以看出,汉字毫无疑问是被看做为一种表意符号的。更准确地说,汉字被认为是一种视觉-语义单元,所以其编码零碎的设计逻辑切实实在与类似英语的拼音文字有着根本性的差异。
格外值得注重的是,CJK 并没有仅仅涵盖内地使用的汉字,还囊括了包括日本国语汉字、和制汉字,韩国韩文汉字,越南喃字,台湾地区和香气扑鼻港繁体汉字等其他使用汉字国家/地区的字形符号,甚至还包括了很多中国少数民族文字的编码,比如西夏文、契丹小/大字、女书等等等。
一个著名的只存在于 Unicode 里的幽灵汉字:彁
这种跨地区的标准和初期制定标准流程的细致会导致出现一些匪夷所思的离谱情况。因为初期技能限定,手写录入地名时因油墨感化或照片隐约,导致“彊”右半部误录为“哥”,最终使“彁”这一错误字形被收入Unicode。“彁”就是这么一个著名的只存在于 Unicode 里,但是现实中没有存在的幽灵汉字。
导致统一个字字形区别的诸多因素,图源《中文信息处理技能》
我们很容易想到,很多“汉字”词在没有同语言中可能具有完整相反的字形,Unicode 的编码没有考虑没有同语言的语义成绩。比如日语中的“娘”(女儿或年轻女性)与汉语中的“娘”(母亲)语义完整没有同,其编码却都是 U+5A18。
那么如果是一个只具有略微差别的字形呢?会导致字形产生细微差别的因素有很多,比如笔划的偏向、长度、曲度的区别,笔划相交、合并与否,个别笔划的增减、笔划方式的差异等。这些没有同标准字符集中细微的字形区别,在所谓的“表音文字”字符集中没有能说完整没有,但很少见,但是在东亚表意文字中,这就成了需要妥帖办理的核心成绩之一。

“剑”字的六种字形变体,图源《中文信息处理技能》
比如“剑”字有至少如图所示的六种没有同的字形变体,大陆一般用“剑”,日本一般用“剣”,台湾地区一般使用字形则为“劍”,但是他们的 Unicode 编码是统一的,亦即只要是字形相似、字源相反、语义相关的汉字,就在统一个码位上。
字形显示的基来源根基理:从离散点阵位图到参数化曲线矢量图
Unicode在本质上定义的是字符的抽象身份(Identity),而非它的具体字形。而我们或多或少接触过的“字体”文件,贮存的就是字符的没有同字形。操作零碎经过字体文件,把特定unicode码位的字形渲染出来,就呈现出我们在屏幕上看到的样貌了。

点阵字形示例图,同上
作为二维立体图形,决定汉字字形的要素异常复杂,至少包括有笔划层面上的基础笔形(横竖撇捺钩等)、静态笔势(笔划偏向轻重)、空间干系(交织/相接/断开)等,构件层面上的相对地位、形变规则(没有同偏旁部首组适时大小变化)、嵌套层次,整体层面上的视觉均衡、密度谐和、风格等。
在文字处理技能的初期阶段,字形信息的数字化纪录的通用办理方案是离散点阵位图。其基础技能道理很简单,即把字形分割为小正方形栅格矩阵,对于其中的每个点阵单元都可以用坐标纪录其地位,用有色(1)和无色(0)纪录其状态并对之举行二值化信息编码。

笔划矢量压缩法示例图,同上
而基于矢量的方案很快厥后居上。为二维汉字立体图形建立笛卡尔坐标系,纪录每个笔划始点与尽头的坐标后,很容易用向量表示所有笔划和空笔划的偏向与长度。但显然,如果只有端点坐标的话,笔划只能被纪录下静态轮廓,更多的笔势信息变化是根本无法被纪录的,而用控制点定义平滑途径的贝塞尔曲线能够办理这个成绩。参数化曲线很快发展成为矢量方案的核心技能。跟着技能的进一步发展,使用二次贝塞尔曲线形貌字形轮廓的TrueType(.ttf)和三次贝塞尔曲线的OpenType(.otf)已经成了现今最通行的矢量字体技能手段和字体文件格式。

ttf、otf 等是现在最通行的字体文件格式
字形的向量就是字体文件贮存的数据,末了屏幕上渲染出的字形则是把向量复原。没有难想见,字符集范围巨大、必须多字节表示的汉字系中文字体与拉丁系西文字体没有仅在内码编码逻辑上有巨大差别,它们的字形数字化方案也判若云泥。一个西文字符一般只需要几十个控制点即可妥帖纪录,但是纪录一般中文字符需要的平均控制点数目是西文字符的十倍之多!
古籍数据库——汉字是开放鸠合,永远无法穷尽
BMP中仅有20902个基础汉字(U+9FA6 至 U+9FFF还包含90个增补汉字),在理论上,这个数目已经能够笼盖99%的一样平常使用处景,但是那看似微没有足道的所谓“1%”却会引发种种各样的成绩。就比如中国人姓名中有非老旧零碎无法识别的非基础汉字生齿多达6000多万,他们一样平常生活的方方面面,曾经都会因为自己起了一个没有编码汉字的倒霉名字而受到影响。为那些起初没有被编码的汉字字符补办“身份证”迫在眉睫。

这些社会成绩都是BMP外汉字惹的祸!
更“要命”的是,Unicode的巨大愿景远没有止于为现存语言体例字符目次,它还有着一种近乎史诗般的重要使命:散落在人类历史长河中的所有文字符号,Unicode 都要为之设计内码。而历史曾经存在过的汉字字符何止千千切切,其数目之巨大、审定之艰难,都是增补事情的巨大挑战。
在BMP外的扩大立体中增补汉字字符的事情,主要是由表意文字小组IRG(Ideographic Research Group)负责,停止2024年公布的Unicode 16.0,IRG已经为CJK增补了将近 7万个汉字字符。

在IRG官网https://www.unicode.org/irg/可以查询他们的事情情况
但即使搁置IRG引起过诸多争议的“字理”“字源”等学术纠纷没有论,扩大立体内码在人们一样平常使用中的最大成绩实在是除了BMP中的20902个基础汉字外,其余的增补即使有了编码,也无法经过一般的输出法输出。

知乎用户“奈白没有弍”总结的Unicode中汉字及相关字符所有占用区段
相较于输出法限定,Windows与macOS的默认字体支撑成绩更加严峻。因为它们也仅支撑BMP汉字,所以扩大字符在普通用户的电子装备屏幕上甚至无法渲染字形,这就是“頫”的类推简化字既无法被一般的输出法打出,在很多用户的屏幕上也显示没有出来的根来源根基因。
即使在专业领域也存在着同样甚至是更多的麻烦。比如在通行的古籍数据库中会用到的字,同样也是即使已经有了编码,数据库中能够调出,但是只要它没有在基础立体上,就依旧无法举行检索、查询、统计等操作,所以实质上与“集外字”没有区别。所以在实际事情事情中,学者们依旧要把这个已有扩大编码的字符改成一个基础立体编码,后续的数据处理才能真正开展。
而这些数目已经足够巨大的字形还仅仅是“楷写字”,“原形字”则在一个更加复杂、难以数据化的层面上。比如仅仅西周金文“宝”一个字的构形,即高达 1060 个。古文字的数字化开发专家刘志基在《数据库古文字研讨论稿》中指出过:
传统文字学研讨的第一手材料是以印刷、墨拓或誊录、刻写等手段构成的纸张等天然物载体形式,材料库文字学研讨的材料是数字化形式的材料库资源。从查询检索的角度看,天然物载体形式的一手材料是以无序次、无条理状态存在的,因此出于特定研讨目的处理,一般都需要人工目验查找、编纂整理。
实在中国大陆早就组织过古汉字编码专家到场IRG的定期会议,但汉字古文字编码的事情依旧希望缓慢。或许这些本来就以非标准形态存在的“原形字”更加鲜明地昭示了表意文字的某种根本特征——正如IRG中处置Unicode和OpenType东亚部分相关事情的专家陈永聪指出的那样,“ IRG的这项事情可能永远都无法停,因为汉字是一个开放的鸠合,它永远没法结束。”
“永没有离职的中华书局员工”——我们这样造出了本没有存在于电脑中的字
如果说编码成绩是理论层面的挑战,那么古籍排版则是这一辩论在实践中的集中体现。学者们对专业数据库的终极盼望是为历史上所有连标准形态都没有的字形建立起靠得住的谱系与可供后续数据处理的标准编码零碎。然而出人意料的是,古籍图书排版专家的志业却与之异若霄壤:“补字补字,我们认为我们补的东西根本就没有是字,我们只是把需要的图片给组合出来。我们的员工就没学过中文的,那些字念什么,是什么意思,我们根本就没有懂,也没有需要懂。我们补字只是为了轻易我们的后续事情,仅此罢了,有任何成绩都由编纂提出、办理,我们只举行后续的批量操作。”
德彩汇智是国内最专业的古籍类图书排版公司。诸如中华书局、北京大学出书社等大名鼎鼎的“古籍出书专业户”,在自己出书社内部实在险些没有排版员工,其古籍类图书基础都是交由德彩汇智举行排版的。公司负责人刘庆伟笑称,自己可以算是“中华书局他们永没有离职的员工”。
在他看来,古籍排版是一种市场范围与需求都异常小、技能含量没有高、附加值也很低的事情,所以“我就只能用改换形式的方式完成客户的要求。”
在2005 、2006年前后,中华书局有了自己的照排室,并最先答应社内与社会上的社外人员合作,刘庆伟也恰是在这个时候就最先了与中华书局的长时间合作。
现今通行的"CTP"(computer-to-plate,直接制版技能)大大降低了排版技能的本钱与难度。然而在当年,排版需要把文件先做到胶片上,晒版(曝光)后还需要做到PS版(Presensitized Plate,预涂感光版)上才能成为印刷机可以使用的印版,这就叫激光照排,是一项相当复杂与烦琐的技能。
刘庆伟还记得当年事情时人人均需常备一本《北大方正汉字内码字典》,片霎没有得离手的景象。当时候的排版人员要想完成事情,是需要自己死记硬背所有待排文字的编码的,他直言当时做排版“异常受罪”。
《北大方正汉字内码字典》
图书排版的本质是图文设计,里面也可以再细分出很多专门的门类,每个门类的排版都有自己的特性和门道,比若有专做辞书排版的,也有专做杂志排版的、科技类图书排版的等等,古籍类排版也是其中比较特殊的一块。
起初刘庆伟没有懂行,想着眉毛胡子一把抓,什么类型的排版都干,结果很快发明没有同类别的排版技能要求区别很大。更重要的是,最初的时候照排是个异常集中的事情,也是出书社对外合作的一块重要营业。当时很多出书机构没有特殊的干系和手段,就很难开启合作,即使荣幸开启了也保持没有住。但与很多其他排版领域挤都挤没有进去的状况比拟,古籍排版却是压根险些没人愿意碰。
古籍类图书的生产周期异常长,一般回款要等到图书正式出书以后,所以回款周期也特别慢,比如黄天树《甲骨文摹本大系》一书就耗时整整近十年时间才最终出书。
虽然厥后国家出台了“没有得拖欠中小企业款项”的政策使得回款情况有了些许好转,但利好也仅限于款项需要报备的项目类图书,如果黑白项目类图书,回款成绩则会依旧让人叫苦连天。古籍排版需频繁点窜,但排版人员仅负责图文设计,内容审校由编纂完成。所以出书方每重新审校一次前往来的稿子,的确就跟一本旧书一样。
而古籍排版最麻烦的地方是别说每个出书社、每位图书编纂,就算是具体到每一本书,他们收到的要求都很没有一样,所以基础无法建立高度标准化、可简单套用的事情流程。所以德彩汇智最终定下自己的主业,就是仅仅专心办事于少数几家靠谱的古籍类出书社。虽然客户是越做越少了,但如果他们建立起自己的专业事情流,这就是一块别家很难分走一杯羹的市场。
任何稍有古籍文本录入经验的人都知晓使用形码录入的速度比使用音码高很多。古代音码输出法输出速度的提升主要依赖于其强大的词频记忆与云词库功能,但这些功能对于包含有大量的生僻字、以单字词为主的古籍文本来讲,输出速度的提升可谓收效甚微。从前古籍排版工基础都是使用五笔输出法的,但跟着期间的变迁,现在已经险些找没有到可以熟练使用五笔输出法的年轻人了。但是即使形码输出有这么大的好处,他们也依旧决定取消员工的五笔培训环节。这是因为古籍图书的可办事客户太少了,它本质上是一个需大于求的市场,提升员工的事情速度也没更多项目可接,所以提升员工的事情服从对公司来讲甚至没什么真正的意义。而补字,就是古籍图书排版事情流中最重要的环节之一,难倒是没有难,但它是一项格外需要大量经验与既有结果积存的麻烦事。
在出书行业有三个最支流排版软件,离别是ID(InDesign),方正书版与方正飞行,其中古籍排版用的基础上都是方正书版。实在字库的重要性要高于软件自己。方正书版最重要的是可以兼容它自己的大型字库GB方正超大字符集。而且最重要的是方正超大字符集中字形显示在电子屏幕上是完整一般的,电子阅读完整没有受影响,但是如果用其他的排版软件和方正的字库举行印刷,就会出现字体笔划偏细的成绩。而且如果排版部分用的是方正字库,那些下游的印厂也必须用。方正超大字符集V 2.0的字库范围更大,但因为价格太高,实在能用得起的排版机构很少。与方正比拟,ID虽然兼容的字更多,但是它只能兼容宋体字,变化模式比较少。更重要的是,方正书版的编纂器黑白所见即所得(Non-WYSIWYG)编纂器,所以它的编纂速度是明显快于所见即所得(WYSIWYG)逻辑的ID的。特别当调入、编纂大文件时,ID仅仅显示文件的渲染效果都要耗时很久。所以在古籍排版这个行当,如果没有是客户有特别的要求,一般排版都要用方正书版,特别是如果末了还有进其他数据库的要求的话。
纯真的补字方法就像“頫”的类推简化字制法一样简单,可以拿字形组图片。组出的图片叫做图字,因为图片是流动高度的,一般的实体书里有大字、小字,图片只要放大减少就会出成绩,所以图字是一种比较麻烦的补字方式。方正书版专门的补字插件女娲补字可以在肯定程度上幸免这些成绩,其道理相当于把与一个既有字体编码对应的字形更换成全新的字形,这个补字可以保存其文本属性并配适格式变化。当然这个编码对应的文字只能在方正书版中识别出来,用一般的复制粘贴手段是复制没有出来的。
更麻烦的照样字体成绩,字体没有同的全都要补一个单独的字,没那么智能,所以种种字体都得造一个。在补字比例较低的时候,如果字体差别较大就容易看出来,而方正书宋和宋体差别较小,这样字体上没有容易看出区别,就能淘汰排版时补字的事情量。正因云云,市面上的古籍大多数都是宋体字。
当然古籍排版里面又可以细分为几类,比如古文字、简牍、俗字等等,每类又都有自己的难处。比如在简牍类图书中,理论上统一个字的字形是没有一样,这些字形每个都需要专门造个字出来。又比如像金甲文字,已经有隶定字的还好些,可以直接换字模,但更多的是没隶定的,而因为它们没有是“方块字”,拿一般组字方法又没法组出来,那就只能做成图字了。
刘庆伟刚入行时,因为没有任何已有补字结果的积存,险些每排一本图书,就得自己完整从零最先新补几千个字,做得头都大了。而且直到现在,古籍出书社为每个需补字领取的报酬,也是很难笼盖新造一个字的本钱的。出书机构为排版公司领取报酬的模式一般是以页为基准,其余剩下的补字是按个领取。为了能够重复行使已有结果,他们自己专门做了一个字库,这样积存的补字多了,以后才可能可以抹平补字的“损失”以致获取利润。实在还有一类更麻烦的类型是关于俗字图书的补字。比如张涌泉的《汉语俗字丛考》,这本书里处处都是需要补字的俗字,更枢纽的是这些新造字在其余的书里险些无法重复行使,这本书也成了刘庆伟职业生活生计里最令自己头疼的事情项目之一。
从“赵孟頫”的简化字争议到古籍排版中的补字困难,这些技能障碍共同揭示了表意文字体系与数字编码规则间的深层辩论——汉字的开放性、编码的统一性、技能的便捷性,如统一个弗成能三角,至今仍在守候更优的办理方案。
公布于:上海市![[聚合]一场农业产业论坛上,中国、沙特两国企业及机构签署70余个合作协议](/images/news_pic/3.jpg)
![[推荐]市场监管总局等五部门约谈外卖平台企业](/images/news_pic/9.jpg)
![[万象]大湾区跨境金融纠纷亟待高效解决机制](/images/news_pic/12.jpg)
![[环球]Steve Madden成立合资企业拓展中国市场](/images/news_pic/30.jpg)
![[城市]中石油原董事长王宜林,一审被判13年!](/images/news_pic/8.jpg)
![[万象]突然暴跌87%!关税,重大影响!](/images/news_pic/1.jpg)
![[万象]刚刚!京东、美团、饿了么等,被约谈!](/images/news_pic/22.jpg)
![[推荐]熵基科技:公司导购机器人等处于实地零售场景测试阶段](/images/news_pic/27.jpg)
![[推荐]昆仑万维正式开源Matrix-Game大模型](/images/news_pic/28.jpg)
![[聚合]宁德市市长张永宁,拟任市委书记](/images/news_pic/5.jpg)
